Our Goal
Finding affordable apartments is hard. We may not be able to influence rental prices but at least we can bring some transparency into the market. Our goal: We want to collect apartment listings with corresponding meta information like rental prices, square meters and location. To achieve this we will:
- Crawl wg-gesucht.de
- Write the results to a
sqlitedatabase - Write a small Django to serve our scraped data as a dashboard
You can find the source code on Github. The final result will looks like this and can be accessed under this link:
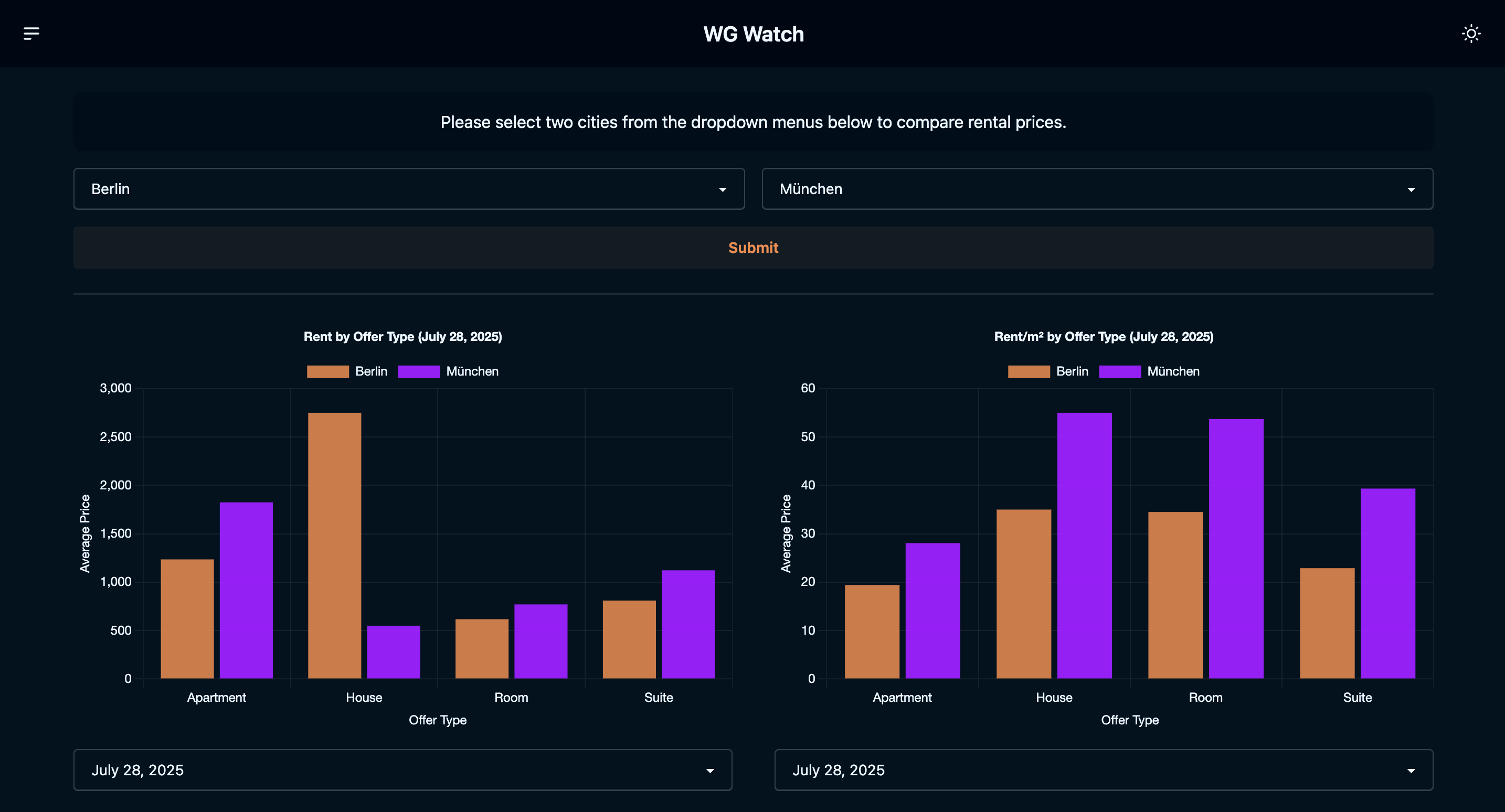
This part of my series deals with the actual scraping.
WG Gesucht?
The German abbreviation “WG” (Wohngemeinschaft) translates to “shared flat” and if you’re looking for one you can try your luck on wg-gesucht.de. Despite its name wg-gesucht not only offers shared flats but also offers apartments for rent:
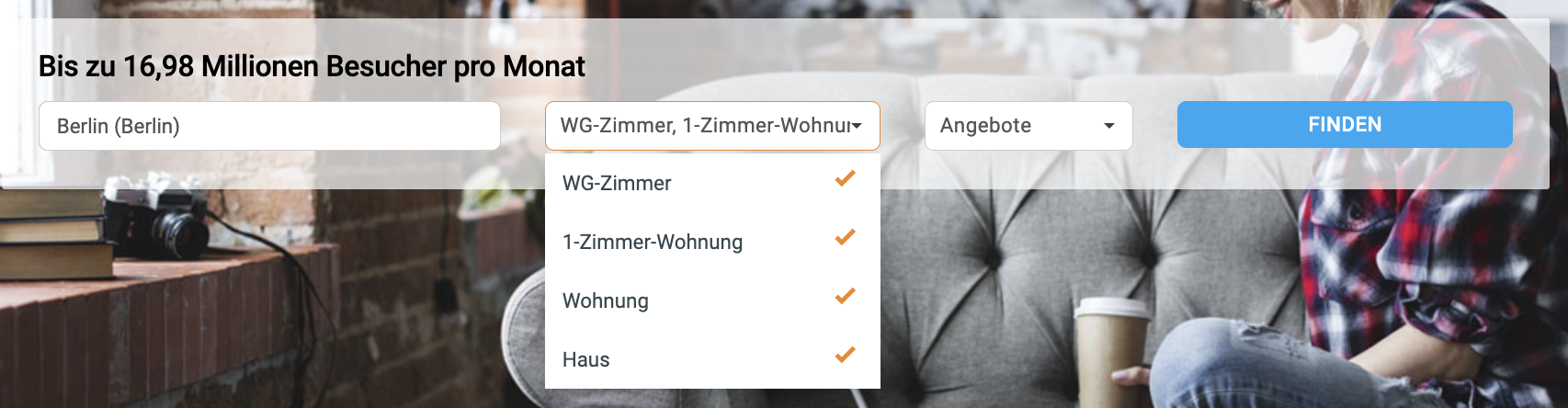
- WG-Zimmer = Shared flat
- 1-Zimmer Wohnung = One-room apartment
- Wohnung = Apartment
- Haus = House
Let’s Inspect the HTML…
The network tab in Chrome DevTools doesn’t reveal any API we could directly query, but looking at the HTML of a search result for apartments in Berlin we see that listing data is embedded as JSON-LD:
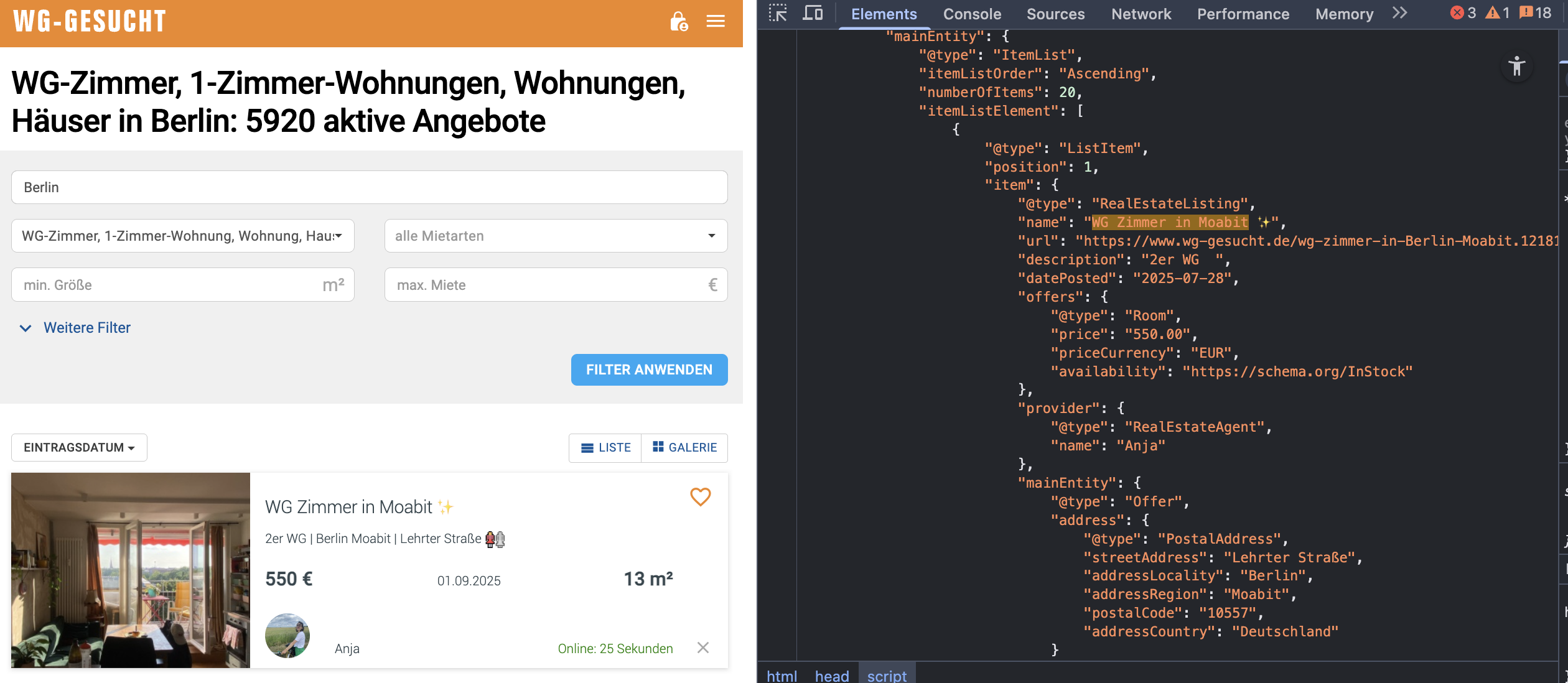
Interestingly the square meter information is not part of this JSON, but only part of a div:
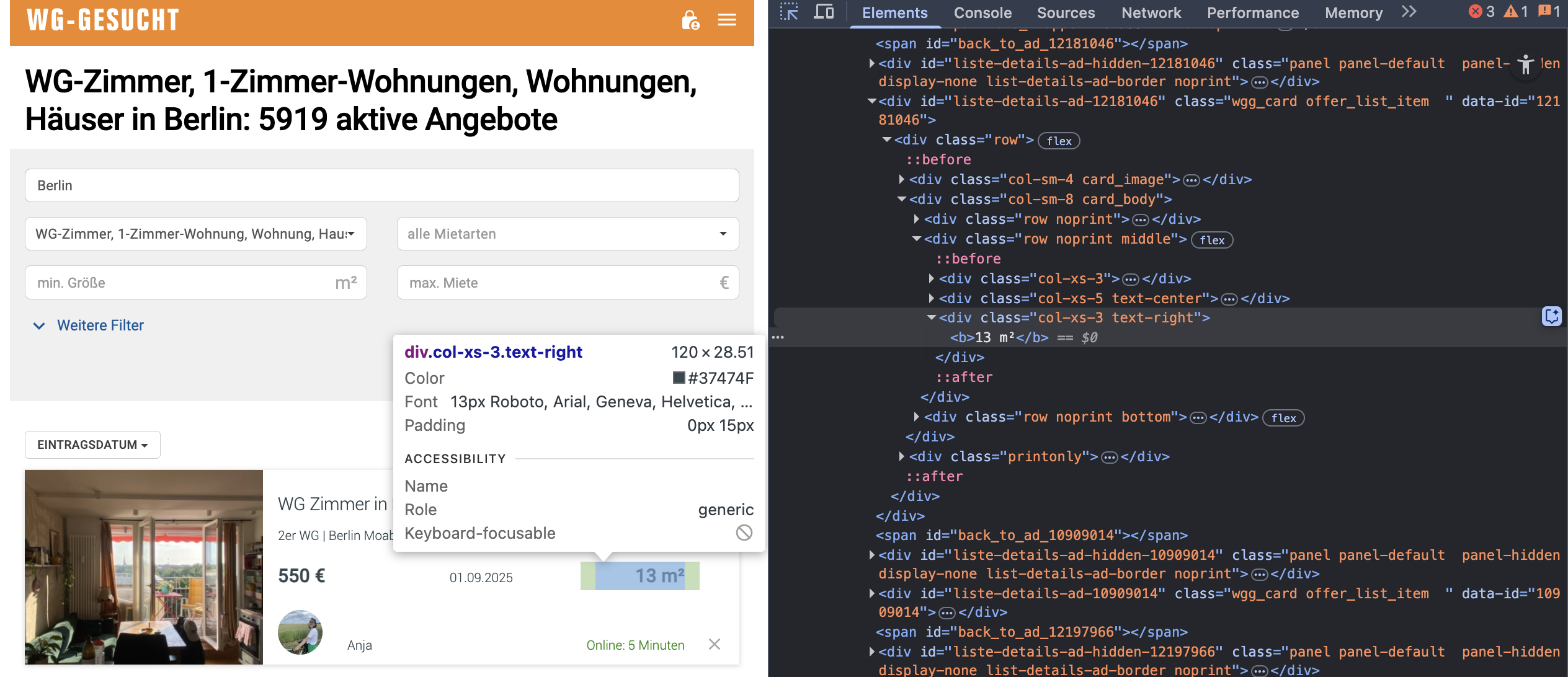
This div has the id liste-details-ad-<LISTING-ID> and the listing id is also part of the URL field in the above JSON, so we can easily link these two parts.
Last but not least we wil need to loop over the result pages. At the bottom of the page we find a div with id assets-list-pagination which gives us information of how many pages of results we can scrape:
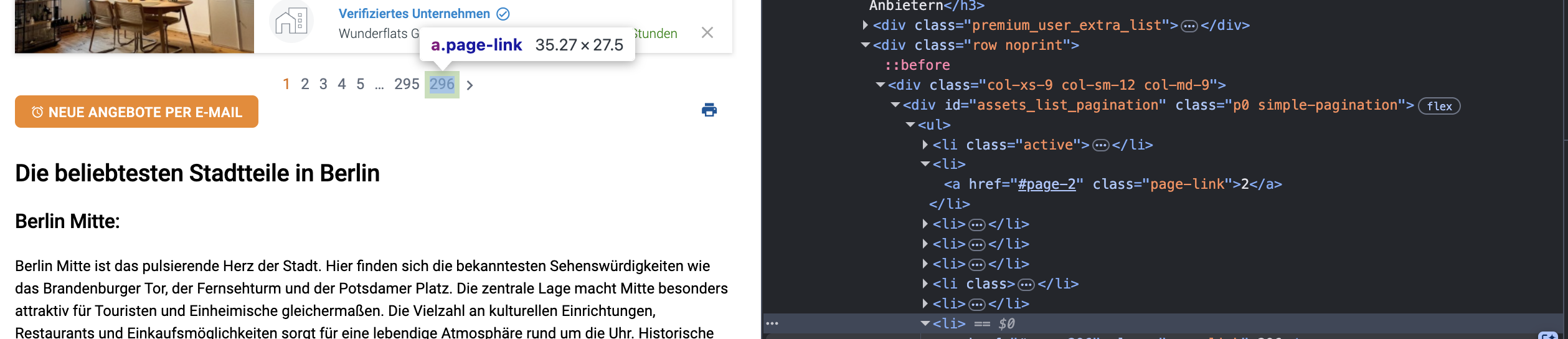
That’s enough for us now, we can work with that.
…And the URL Too
We can parameterize the search result URL with these parameters:
- city
- city_id
- page
In my code I simply use a templated string:
URL_TEMPLATE = (
"https://www.wg-gesucht.de/wg-zimmer-und-1-zimmer-wohnungen-und-wohnungen-und-haeuser"
"-in-{city}.{city_id}.0+1+2+3.1.{page}.html?offer_filter=1"
"&city_id={city_id}&sort_order=0&noDeact=1&categories%5B%5D=0"
"&categories%5B%5D=1&categories%5B%5D=2&categories%5B%5D=3&pagination=4&pu="
)
We are going to query all listings without further filters.
Let’s Scrape
The scraper in itself is quite simple. I am using Zendriver for scraping via Chrome and parse the scraped HTML with Beautiful Soup.
Running the scraper will:
- open multiple Chrome instances and scrape the site for you
- load & parse the HTML
- write the extracted data into a local SQLite database.
This is how it looks:
After a while you will run into Captchas:
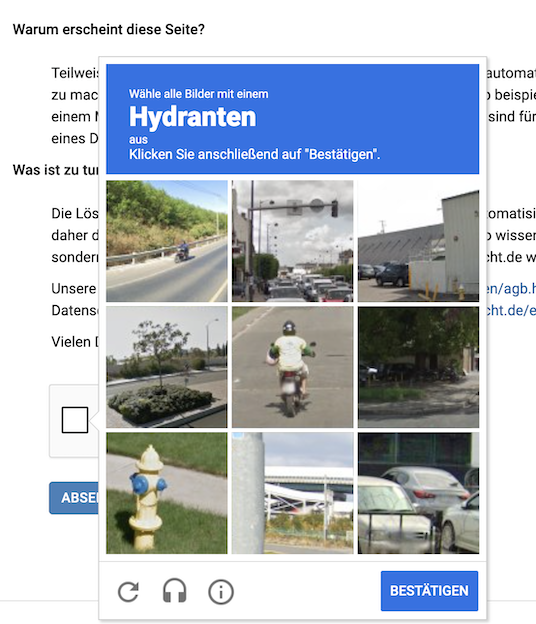
My script currently detectes when a Captcha page pops up and stops scraping while waiting for the user to manually solve the captcha. After that scraping for the corresponding page will continue. It might be worth checking out SeleniumBase which might be able to bypass Captchas.
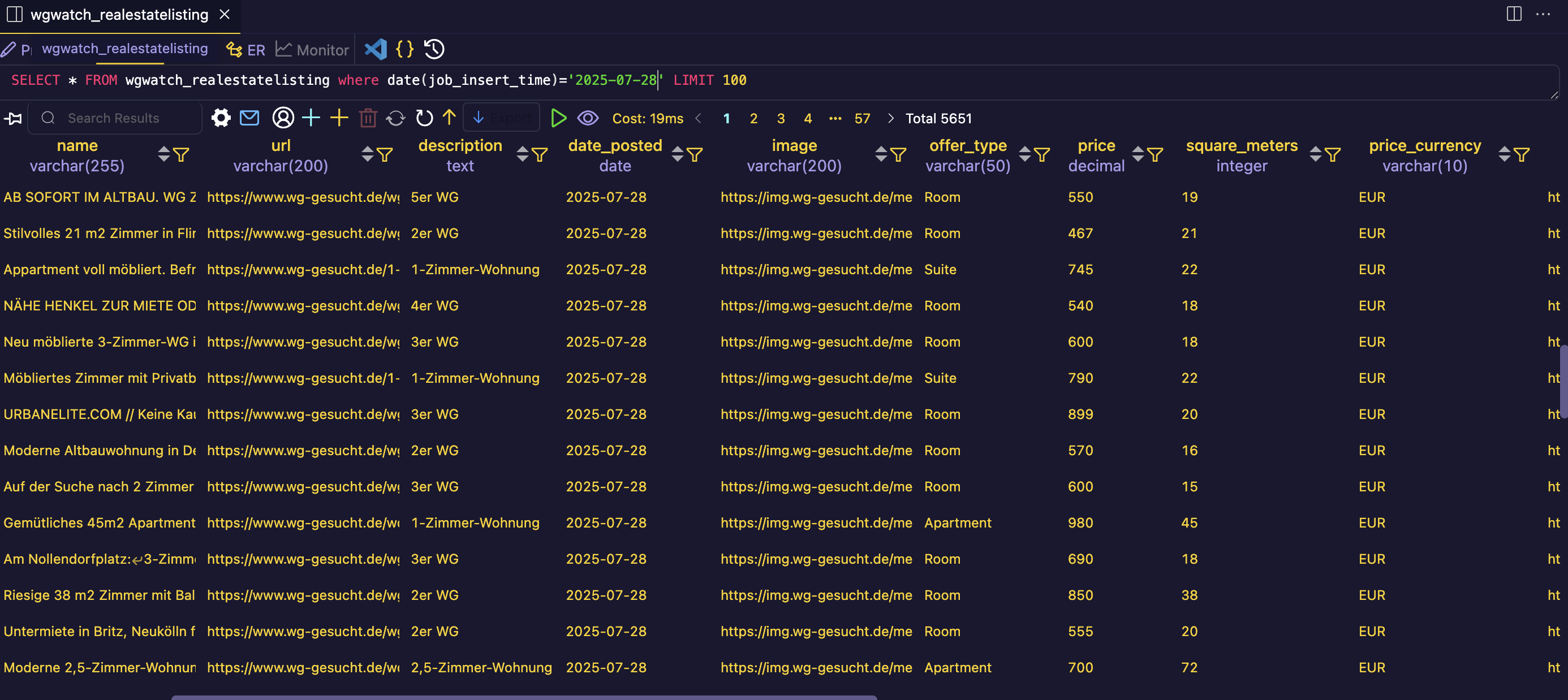
Result: A Database of Apartment Listings
After our scraper has finished its job we will see that our table in SQLite has filled up with listing data:
Part II: Building a Dashboard
That’s it for this part! Now that we’ve got our data collected we’d like get some insights into rental prices. Therefore in the upcoming part II I will show you how I’ve built a small UI using Django, daisyUI & Alpine.js to visualize our scraped data.